Tabellen
Um das Vorgehen beim Erstellen von Datenbanken zu erleichtern, sollen Aspekte
eines Pizza-Services untersucht werden und in einer kleinen Datenbank dargestellt
werden. Dabei wird von einem kleinen Betrieb (ein paar Mitarbeiter, ein paar Autos,
...) ausgegangen.
Um sich dem Thema Datenbanken zu nähern, können wir versuchen die Bestellkarte
als Tabelle darzustellen:
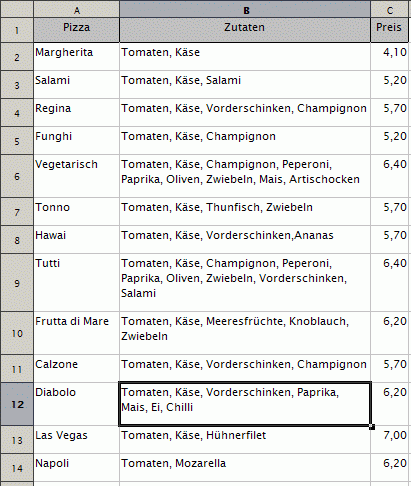
Dieses Bild entstand, indem die Daten der Bestellkarte in eine Tabellenkalkulation
eingegeben wurden.
Anhand der Tabelle lassen sich einige Definitionen, die im Zusammenhang mit
Tabellen immer wieder auftauchen, gut erklären:
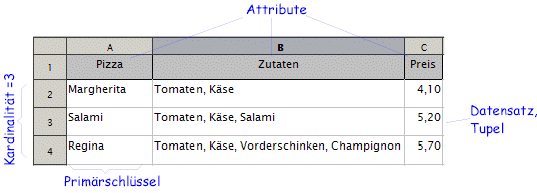
- Die Daten sind in einer Tabelle oder Relation organisiert.
Diese besitzt einen eindeutigen Namen.
(In unserem Fall vielleicht "Bestellliste")
- Eine Zeile wird auch Datensatz oder Tupel genannt.
- Die Anzahl der Datensätze wird Kardinalität der Relation genannt.
- Alle Zeilen haben die gleiche Struktur, wie sie durch die oberste Zeile
vorgegeben wird. Die einzelnen Elemente der obersten Zeile (Pizza, Zutaten,
Preis) heißen Attribute der Relation.
- Jedes Attribut (jede Spalte) kann von einem anderen Typ sein. Pizza ist vom
Typ Zeichenkette, Preis vom Typ Kommazahl. Man sagt auch: ein Attribut gehört
zu einer bestimmten Domäne.
- Die Anzahl der Spalten nennt man degree oder .
- Ein Datensatz muss anhand eines oder mehrerer Attribute eindeutig identifizierbar
sein. Diese Attribute nennt man Primärschlüssel. In unserem Fall
könnte das der Name der Pizza sein.
- Man neigt dazu, Daten redundant abzuspeichern (siehe Spalte Zutaten: das Wort "Käse"
tacuht sehr häufig auf).
- Skalierbarkeit: (Unabhängigkeit der Funktionalität von der Datenmenge)
- Mit der Zahl der Datensätze steigen die Anforderungen an ein
Suchsystem. Da genügt es nicht, nach einem Stichwort zu suchen.
- Es fehlt eine Möglichkeit der Datenfilterung für die Ausgabe.
Alle Nachteile